
truncated BPTT란?
- 원래 backpropogation through time (BPTT)는 gradient가 무한대로 발산하거나, 무한히 작아질 수 있는 문제가 있다. 일명 vanishing and exploding gradients.
- 참고자료1: vanishing and exploding gradients understanding_rnn_lstm
- 참고자료2: RNN backpropagation에 대한 쉬운 파이썬 코드 설명 anyone-can-code-lstm.
아래의 에니메이션(출처 anyone-can-code-lstm)을 확장해서 RNN cell이 수십, 수백개가 연결되어있다고 한다면, 주황색으로 전달되는 에러(학습해야하는 분량)가 이전의 시간으로 전달될수록 점차 희석될 것이다. (색깔의 농도가 에러의 크기를 나타낸다고 가정할 때)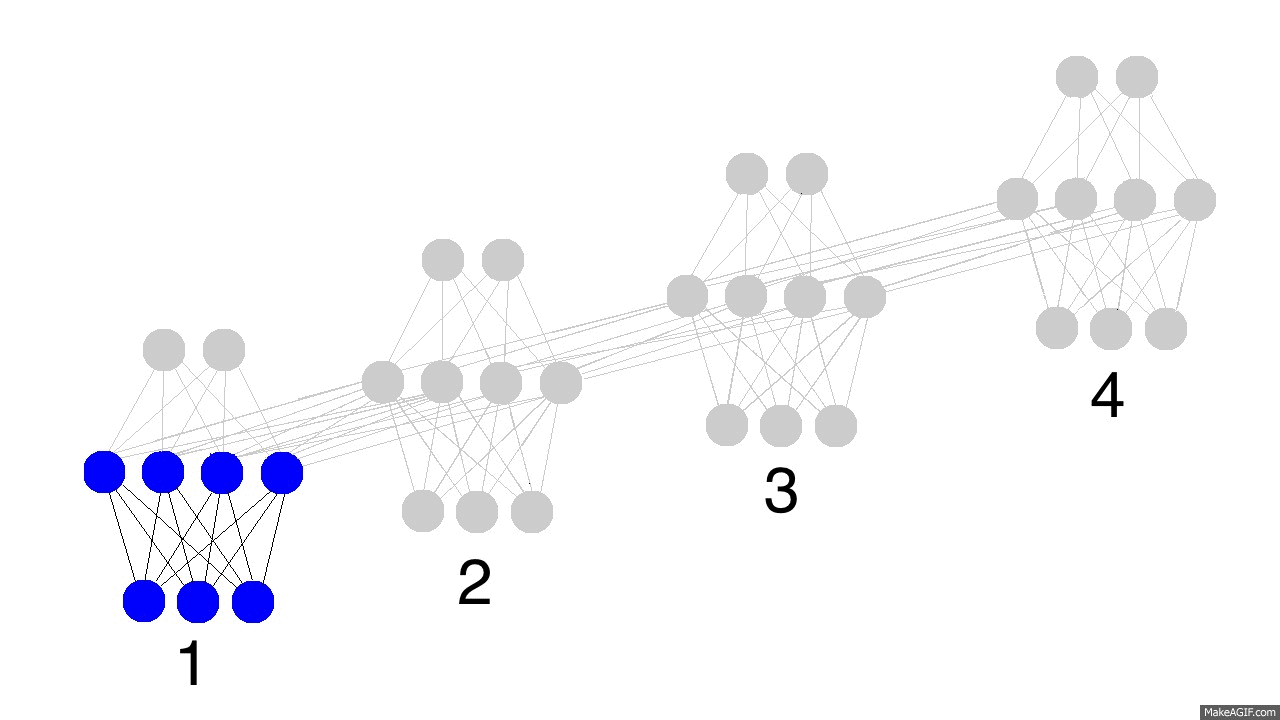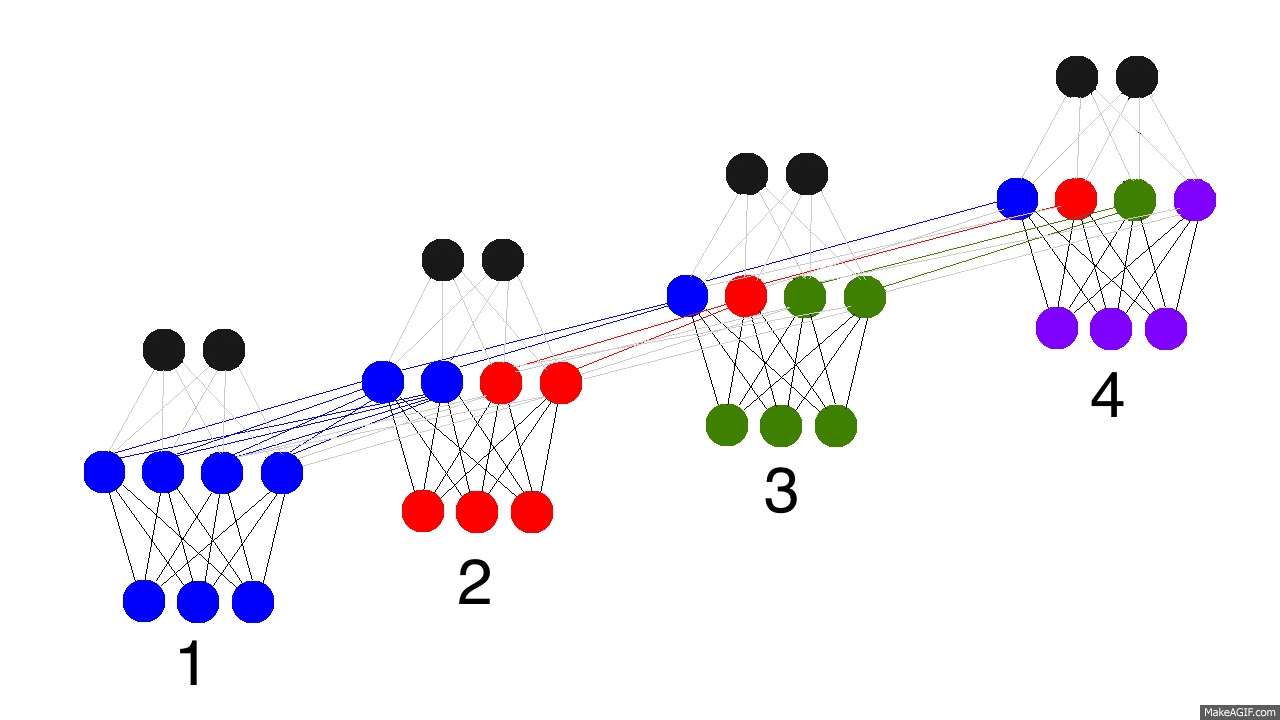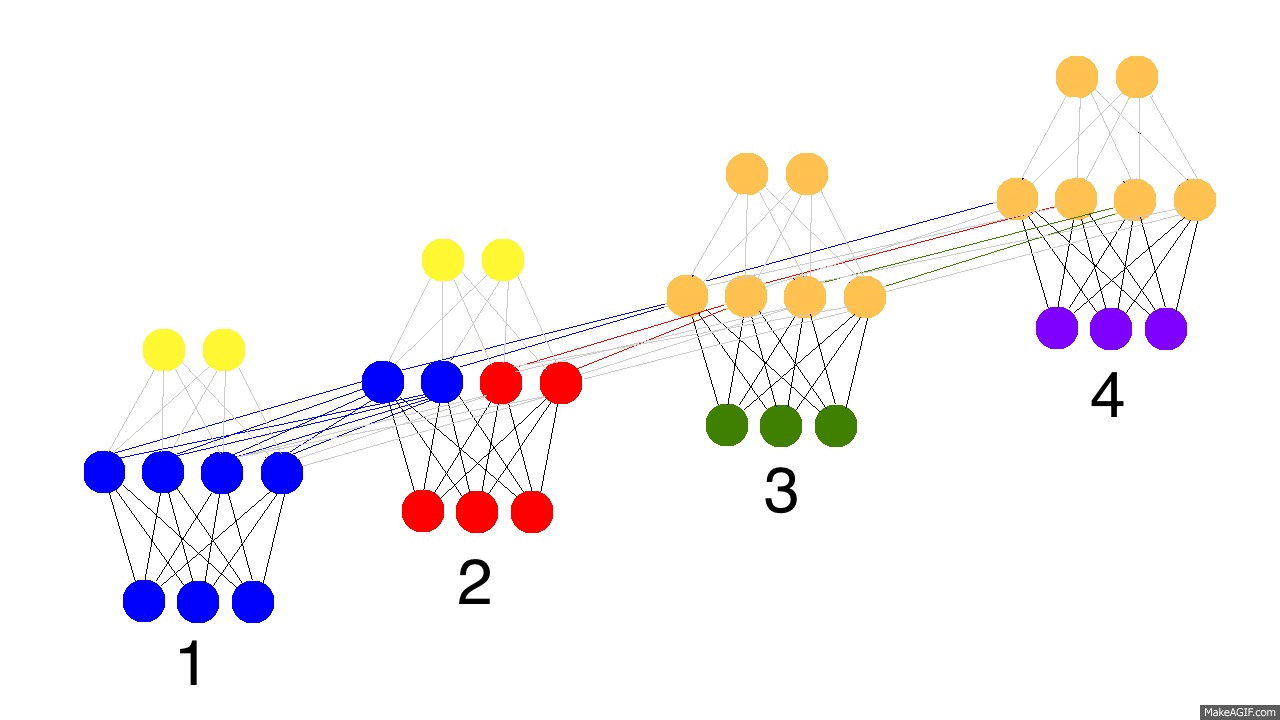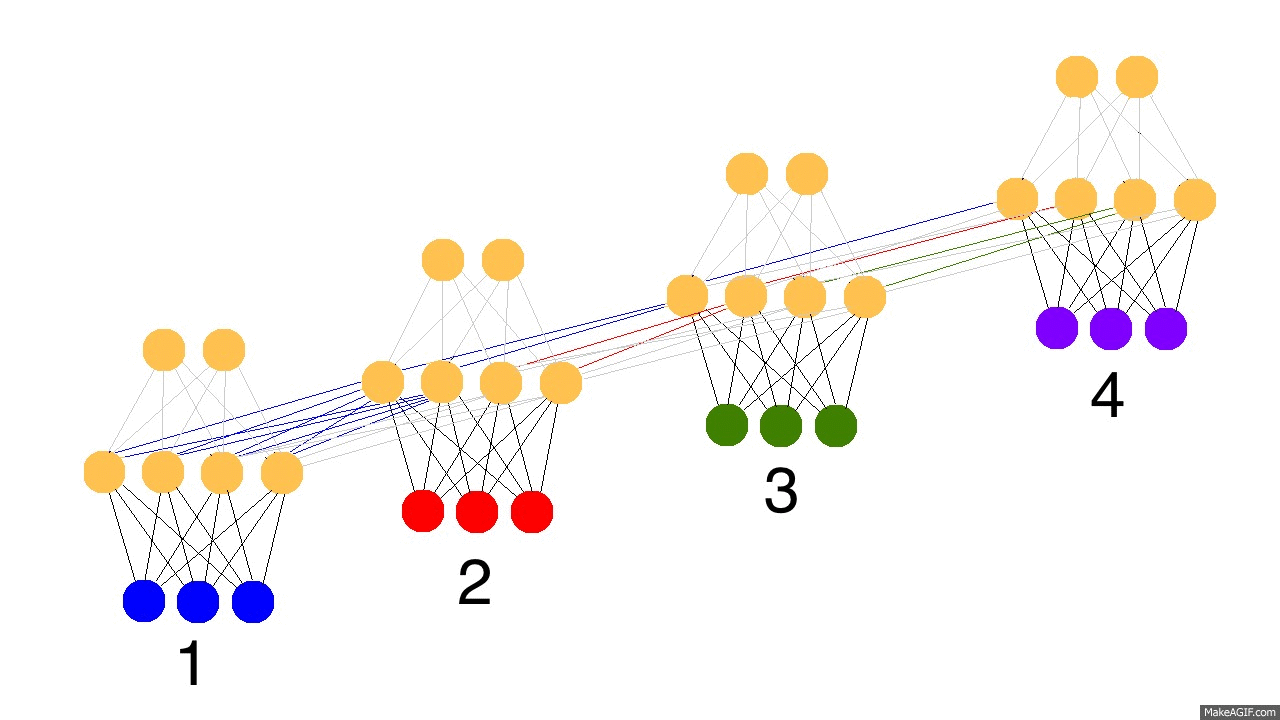
- 에러가 학습패러미터(웨이트와 바이어스)에 잘 전달되지 않으면 아무리 RNN, LSTM과 같은 모델을 사용한다해도 시간 모델링 (time-dependancy modeling)이 제대로 이루어질 수 없다. 반대로 필요하지 않은 이전 정보들까지도 학습하게 돼서 예측이 잘 안될 수도 있다.
- 즉 장기 기억을 적절한 단위로 쪼개서 학습시키자는 것이 아이디어. 이는 vanishing and exploding gradients문제를 해결하면서, 동시에 특정 인풋에 적합한 시간 window를 사용하자는 것으로 해석이 가능하다.
비유를 하자면,
비유1.
1-1. (지금) 배가 아픔 –> (1시간 후) 티비를 봄
1-2. (지금) 배가 아픔 –> (1분 후) 화장실에 감비유2.
2-1. (지금) 담배를 피움 –> (1분 후) 암에 걸림
2-2. (지금) 담배를 피움 –> (10년 후) 암에 걸림각 경우를 이해하기 위한 적절한 시간 단위는, 비유1에서는 ‘1분’, 비유2에서는 ‘10년’이라고 할 수 있다.
위의 비유가 완벽하지는 않지만, 각 사건 (인풋, 데이터 등)마다 시간 프레임이 다르기 때문에, 이를 고려해야한다는 것이 요지. 그리고 그것이 truncated BPTT의 아이디어와 밀접한 연관이 있다.
truncated BPTT의 구현
- truncated BPTT의 구현은 다양한 방법으로 이루어질 수 있다. 사운드에서 MFCC를 추출할 때, window size와 shifting size를 미리 정해줄 수 있는 것처럼, truncated BPTT에서도 BPTT를 얼마나 (시간적으로) 긴 단위에 걸쳐서 할 것인지 (=window size), 그리고 얼마나 촘촘하게 할 것인지 (=shifting size)를 설정할 수 있다.
- 이렇게 BPTT의 촘촘함과 사이즈를 각각 , 라고 표현할 수 있다 (r2rt.com, Ilya Sutskever’s Ph.D. thesis).
- 즉 , 를 적절히 잘 선택하면 얼마나 정밀하게, 그리고 얼마나 길게 시간 관계를 모델링할지를 설정할 수 있다.
- 좀 더 정확히 말하자면, 얼마나 BPTT를 자주 할지가 이고, 얼마나 뒤까지 에러를 전달할지가 이다. MFCC에 비유하자면, 는 shifting size와 유사하고, 는 window size와 유사하다.
- 참고: Pseudo 코드 for truncated BPTT
얼마나 멀리? 얼마나 촘촘히? MFCC window size shifting size truncated BPTT
{kind=link}
- TensorFlow에서는 로 설정한다는 점이 특징적이다 (TensorFlow website, WildML). 즉, shifting을 할 때, 안겹치게 하겠다는 것을 의미한다. 아래 그림 참조(r2rt.com). 길이가 6인 인풋 데이터에서 인 경우.

- 반면 ‘true’ truncated BPTT는 로 설정하고 인풋이 한 번 포워드 될 때마다 BPTT를 하는 경우를 의미한다. 아래 그림 참조(r2rt.com). 길이가 6인 인풋 데이터에서 인 경우

- TensorFlow식의 truncated BPTT는 BPTT를 하는 횟수가 ‘true’ truncated BPTT보다 훨씬 적기 때문에 계산과 처리 속도 측면에서 우월하다는 특징이 있다 (r2rt.com 실험 참조).
- r2rt.com의 BPTT실험에 따르면 ‘true’ truncated BPTT가 TensorFlow의 truncated BPTT보다 조금 더 높은 정확도를 보이지만, 이는 근소한 차이이며 ‘true’ truncated BPTT를 구현하고 훈련하는 것이 비효율적이라는 점을 강조한다. 즉 TensorFlow스타일의 truncated BPTT를 그냥 사용하는 것이 바람직 할 것으로 보인다. 물론 얼마나 ‘촘촘히’ 시간 관계를 모델링할지를 생각한다면 customized code를 작성해야겠지만, 훈련에 걸리는 시간과 효율성을 생각해 볼 필요가 있을 것이다.
Jaekoo Kang