
The KU-CORPUS (ver.2)
1. Introduction
This document is intended to provide an overview of the methodology employed in the creation of the KU Corpus 2 (save dir: inchon26 /home/hdd2tb/KUCORPUS/KUCORPUS_cleaned), including data collection and labelling. The purpose of the KU Corpus was to create a database of 1) 10 American English vowels in isolated words and 2) 8 types of Korean vowels elicited by native Korean L2 speakers of English. The speech data of 56 speakers contained time-aligned phonetic labels. This manual is organized as follows. Section 2 describes aspects of the data collection along with characteristics of the talkers who comprise the corpus. Section 3 of the manual describes how aligned lexical and phonetic transcriptions of the speech were created. Aligning was done in two steps, an automatic aligning phase and manual adjustment of the phonetic and lexical symbol alignment. Conventions for manual adjustment of phonetic symbols may also be found in Section 3. Section 4 describes the file structure and naming convention.
2. Speakers and Stimuli
2.1 Overview
The data collection was conducted as the term project in English Phonetics (Fall 2016) by Prof. Hosung Nam in Korea University. Fifty-six students participated in the data collection.
Using a [self-recording routine (by. Wibaek Kim)] (https://github.com/kwb425/Vowel_Recorder_Praat_and_MATLAB) designed specifically for this purpose, the students were asked to record 10 isolated English words and 8 isolated Korean mono-syllabic segments in randomized order. Each item was recorded 100 times.
2.2 Speakers
Out of the 56 students that succesfully submitted recordings, 2 non-Korean native speaker’s data was excluded from the corpus. Below is the speaker coding of the remaining 54 (32 Female & 22 Male) Korean speakers of the corpus.
| ID | Gender | Name |
|---|---|---|
| f01 | female | 강영비 |
| f02 | female | 고은민 |
| f03 | female | 권도윤 |
| f04 | female | 김경림 |
| f05 | female | 김관희 |
| f06 | female | 김민선 |
| f07 | female | 김소연 |
| f08 | female | 김소진 |
| f09 | female | 김예슬 |
| f10 | female | 김재현 |
| f11 | female | 김지해 |
| f12 | female | 김하린 |
| f13 | female | 김한결 |
| f14 | female | 문수영 |
| f15 | female | 박모현 |
| f16 | female | 박소영 |
| f17 | female | 박지영 |
| f18 | female | 송윤수 |
| f19 | female | 송윤영 |
| f20 | female | 신유경 |
| f21 | female | 신정인 |
| f22 | female | 신주은 |
| f23 | female | 양소영 |
| f24 | female | 원혜진 |
| f25 | female | 윤예림 |
| f26 | female | 이연주 |
| f27 | female | 이선화 |
| f28 | female | 이현미 |
| f29 | female | 이혜인 |
| f30 | female | 채주영 |
| f31 | female | 최윤서 |
| f32 | female | 하윤정 |
| m01 | male | 권효준 |
| m02 | male | 김태윤 |
| m03 | male | 박상준 |
| m04 | male | 박승수 |
| m05 | male | 박주현 |
| m06 | male | 박진우 |
| m07 | male | 박희운 |
| m08 | male | 오현근 |
| m09 | male | 윤호영 |
| m10 | male | 이상명 |
| m11 | male | 이예찬 |
| m12 | male | 이인구 |
| m13 | male | 이주형 |
| m14 | male | 이태훈 |
| m15 | male | 임형섭 |
| m16 | male | 적탁원 |
| m17 | male | 정내혁 |
| m18 | male | 조근식 |
| m19 | male | 최원철 |
| m20 | male | 한석희 |
| m21 | male | 황인규 |
| m22 | male | 황재욱 |
2.3 Stimuli
Two different kinds of speech materials were collected from each speaker in the KU Corpus: isolated English words and isolated Korean words. The isolated English words were hVd words (one exception for food) consisting of 100 repetitions of each of 9 American English vowels in the hVd context: heed hid hey head had hot hope hood food.
2.3.1 10 English Words
| Vowel | Environment | Word | Repeat |
|---|---|---|---|
| iː | hVd | heed | (x100) |
| ɪ | hVd | hid | (x100) |
| eɪ | hV | hey | (x100) |
| ɛ | hVd | head | (x100) |
| æ | hVd | had | (x100) |
| ʌ | hVt | hut | (x100) |
| ɒ | hVt | hot | (x100) |
| əʊ | hVpe | hope | (x100) |
| ʊ | hVd | hood | (x100) |
| uː | fVd | food | (x100) |
2.3.2 8 Korean Syllables
| Vowel | Environment | Word | Repeat |
|---|---|---|---|
| ㅏ (a / aː) | hV | 하 | (x100) |
| ㅓ (ʌ / əː) | hV | 허 | (x100) |
| ㅜ (u / uː) | hV | 후 | (x100) |
| ㅔ (e / eː) | hV | 헤 | (x100) |
| ㅐ (ɛ / ɛː) | hV | 해 | (x100) |
| ㅗ (o / oː) | hV | 호 | (x100) |
| ㅡ (ɯ / ɯː) | hV | 흐 | (x100) |
| ㅣ (i / iː) | hV | 히 | (x100) |
3. Transcription Procedure
The Penn Phonetics Lab Forced Aligner Toolkit (the P2FA) was used to automatically capture the vowel intervals in each word-level recordings. The wav files were down-sampled (44000 -> 11025 Hz) in order to be processed by P2FA. TextGrid files containing time alignment information was created for each wav file.
4. Organization of the Database
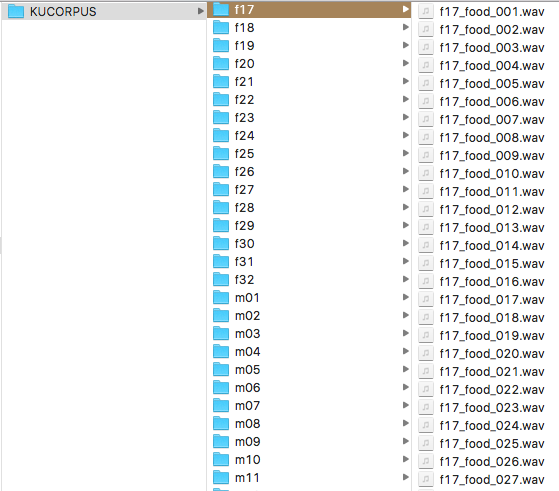
4.1 Folder Organization
The database is organized by subjects. In each subject folder, 1800 (or less) wav files are sorted by the alphabetic word order. The number (001~100) following the word marks which of the 100 repeats the wav file was record from.
(gender)(within-genderID)_(word)_(number).wav
References
The Kucorpus (ver.1) Manual by Yeonjung Hong (2016)
Written by Youngsun Cho (2017) Please send any inquiries to: youngsunhere@gmail.com