
HCLG
- 예전엔 Viterbi search가 phone HMM (H)에만 이용 되었음.
- 즉, 주어진 HMMs 와 acoustic output에 대해, 가장 likely한 input state 열, 즉 가장 likely한 triphone을 찾기.
- t-1에서 best였던 state에 대해서만 t에서 best state찾음
- Kaldi에선 이 Viterbi-like search를 H 뿐 아니라, C L G 전체에서 수행
- H C L G를 wfst format으로 G부터 하나씩 cascade방식으로 결합
- HCLG로 결합된 방대한 HMM graph는, 너무 커 beam-pruning 방법으로 threshold아래의 점수를 보이는 state는 search에서 제외.
H (HMM)
input: HMM state sequence
output: triphone
weight: HMM transition probablity
- H에는 모든 triphone에 대해 state sequence가 정의되어 있음
- L에서 모든 단어에 대해 phone sequence가 정의되어 있는 것과 동일
- 각각의 state는 고유한 39 MFCC-GMM (pdf) 을 참조하고 있음
- acoustic signal로부터 한 frame은 feature vector (e.g. 39의 MFCC values)로 이루어짐.
- 이 feature vector는 각 state마다 정의된 39개의 GMM의 input으로 들어가 39개의 확률값으로 output되어 나옴.
- 39개의 output값의 곱은 각 state의 observation probability가 됨
- 따라서 한 frame의 feature vector로부터 모든 가능한 state의 observation probability가 계산됨
- 모든 state의 observation과 transition probability가 정의되어 있는 상태.
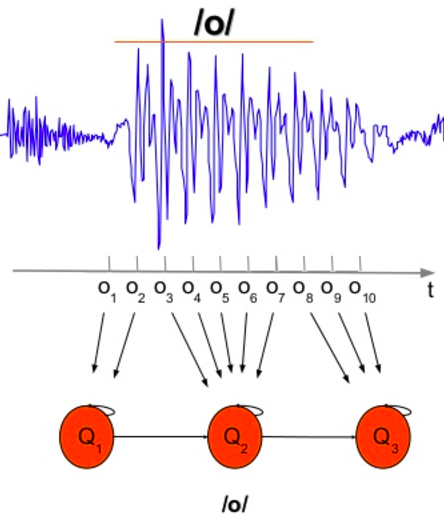
- 주어진 frame 열에 대해 obs와 trans 확률의 모든 곱을 최대로 하는 state 열을 찾으면 된다.
C (Context dependency)
input: triphone
output: phone
weight: n/a
L (Lexicon)
input: phone sequence
output: word
weight: pronunciation probability
- L에서 composition/minimization 효율을 위해 첫 phone에서 word로 변환.
- 각 단어의 끝에서 silence를 선택적으로 처리할 수 있게 sil state을 거쳐 가게 함.
- 같은 발음인 두 단어를 determinable하게 하기 위해 단어 끝에 #1, #2 넣어 줌.
G (Grammar)
input: word sequence
output: word sequence
weight: n-gram probability
Hosung Nam